Web Scraping With Python Using Selenium and Beautiful Soup
In this article, I want to show you how to download and parse structured data from the text of a website. It is a gentle introduction those who have wanted to deal to get started with Web Scrapping and building their own datasets, but did not know where to dig in.
What Is Web Scraping?
Web scraping is the practice of automatically retrieving the content of user-facing web pages, analyzing them, and extracting/structuring useful information. Sometimes this is necessary if you need to retrieve data from a resource (perhaps a government website), but a URL for fetching a machine readable format (such as JSON or XML) is not available. Using a scraper, it is possible to "crawl" the pages of the site, read the HTML source, and extract the pieces of information in a more machine friendly format.
Everything that I've described can certainly be done manually, but the power of scrapers is that they allow you to automate the process. Mature scraping programs, such as Selenium, allow for you to automate all aspects of data collection. This might include specifying a URL to visit, elements in the page to interact with, and even ways to simulate user behavior. Once the specifics of the "session" are defined, you are then free to run the script hundreds, thousands, or millions of times.
Even though scraping is extremely powerful, this is not to say it is an easy task. Websites come in many different forms, and many websites need love and care in order to find and retrieve information. Further, there are many parsing libraries available, with large variability in terms of functionality and capabilities. In this article, we will look at two of the most popular parsing tools and talk about how they are used.
Static and Dynamic Scraping, What's the Difference?
First, though, let's talk about the two major types of scraping: static and dynamic.
- Static scraping ignores JavaScript. It pulls web pages from the server without using a browser. You get exactly what you see in the "page source" and then you cut and parse it. If the content you're looking for is available without JavaScript, then using the popular Beautiful Soup library is an ideal way to scrape static sites. However, if the content is something like iframe comments, you need dynamic scraping.
- Dynamic scraping uses an actual browser (or headless browser) and allows you to read content that has been generated or modified via JavaScript. Then it asks the DOM to fetch the content you are looking for. Also sometimes you need to automate the browser by simulating the user to get the content you want. For such a task, you need to use Selenium WebDriver.
Static Scraping With Beautiful Soup
In this section, we will look at how you can scrape static content. We'll introduce the Python library "Beatiful Soup," discuss what it is used for, and a brief description of how to use it.
Beautiful Soup is a Python library that uses an HTML/XML parser and turns the web page/html/xml into a tree of tags, elements, attributes, and values. Once parsed, a document consists of four types of objects: Tag, NavigableString, BeautifulSoup, and Comment. The tree provides methods / properties of the BeautifulSoup object which facilitates iterating through the content to retrieve information of interest.
Step 0: Install the Library
To get started with Beautiful Soup, run the following commands in terminal. It is also recommended to use a virtual environment to keep your system "clean".
pip install lxml pip install requests pip install beautifulsoup4
Step 1: Retrieve Data From a Target Website
Go to the code editor and import the libraries:
from bs4 import BeautifulSoup import requests
To get acquainted with the scraping process, we will use ebay.com and try to parse the prices of laptops.
First, let's create a variable for our URL:
url = 'https://www.ebay.com/b/Laptops-Netbooks/175672/bn_1648276'
Now let's send a GET request to the site and save the received data in the page variable:
page = requests.get (url)
Before parsing, let's check the connection to ensure that the website returned content rather than an error:
print(page.status_code)
The code returned us a status of 200, which means that we are successfully connected and everything is in order.
We can now use BeautifulSoup4 and pass our page to it.
soup = BeautifulSoup (page.text, "html.parser")
Step 2: Inspect the Contents of the Page and Extract Data
We can look at the html-code of our page:
print(soup)
Let's get back to our task.
Let's start by writing a function that will make a request for the specified link and return a response:
def get_html(url): response = requests.get(url) return response.text
The page displays 48 products, all of them are located in the <li> tag with the s-item class. Let's write a function that will find them.
def get_all_items(html): soup = BeautifulSoup(html, 'lxml') items = soup.find("ul", {"class": "b-list__items_nofooter"}).findAll("li", {"class": "s-item"}) return items
While the page has a lot of different types of data, we will only parse the name of the product and its price. To do this, we will write a function that will accept one product as input. Using the h3 tag with the b-s-item__title class, get the name of the product and find the price in the span with the s-item__price class
def get_item_data(item): try: title = item.find({"h3": "b-s-item__title"}).text except: title = '' try: price = item.find("span", {"class": "s-item__price"}).text except: price = '' data = {'title': title, 'price': price} return data
Next, we will write another function with which we will write the data that we received to a file with the csv extension:
def write_csv(i, data): with open('notebooks.csv', 'a') as f: writer = csv.writer(f) writer.writerow((data['title'], data['price'])) print(i, data['title'], 'parsed')
Putting all the pieces together in a main function, we can create a simple program which will connect to Ebay and retrieve the first five pages of laptop data:
def main(): url = 'https://www.ebay.com/b/Laptops-Netbooks/175672/bn_1648276' for page in range(1, 5): # count of pages to parse all_items = get_all_items(get_html(url + '?_pgn={}'.format(page))) for i, item in enumerate(all_items): data = get_item_data(item) write_csv(i, data) if __name__ == '__main__': main()
Once the program finishes running, we will receive a file with the names of goods and their prices:

The example above is the most basic information needed to familiarize yourself with the Beautiful Soup library. Most real-world scraping problems are more complex, and require that you retrieve a large amount of information within a fairly short time frame. If that is the case, Beautiful Soup can be used alongside the multiprocessing library, which allows you to run multiple threads (each of which can retrieve and parse data in parallel), which will significantly increase the parsing speed.
Dynamic Scraping With Selenium WebDriver
In this section, let's do some dynamic scraping.
Consider a website that sells game cards. Unlike Ebay, which sends fully formatted HTML, the card game website uses a single page architecture which dynamically renders the data via JavaScript templates. In this case, if you attempt to parse the data using Beautiful Soup, your parser won't find any data. The information first must be rendered by JavaScript.
In this type of application, you can use Selenium to get prices for cards. Selenium is a library which will interface with the browser, allow for the site to render, and then allow you to retrieve the data from the browser's DOM. If you need to, you can script the browser to click on various links to load HTML partials that can also be parsed to get additional detail.
Step 0: Set Up Your Program
Here are the required imports.
import csv from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager
get_page_data() function accepts driver and url. It uses the get() method of the driver to fetch the url. This is similar to request.get(), but the difference is that the driver object manages the live view of the DOM.
Step 1: Determine How to Parse the Dynamic Content of the Page
For the website in our example, the next step is to select the country and the number of prices on the page.
Note that we expect the page elements to be present as the content is loaded dynamically and will not necessarily be immediately available. To prevent the program from moving on without finding and retrieving the data, we can use WebDriverWait.
Then we look for the block where the prices are located using the product-listing class:
def get_page_data(driver, url): driver.get(url) btn_country = WebDriverWait(driver, 20).until( EC.presence_of_element_located((By.CLASS_NAME, "btn-link")) ) btn_country.click() select_country = WebDriverWait(driver, 20).until( EC.presence_of_element_located( (By.XPATH, "/html/body/div[5]/div[4]/div/div/div[2]/form/select/option[208]")) ) select_country.click() save_country = WebDriverWait(driver, 20).until( EC.presence_of_element_located( (By.XPATH, "/html/body/div[5]/div[4]/div/div/div[3]/button[1]")) ) save_country.click() line_count = WebDriverWait(driver, 20).until( EC.presence_of_element_located( (By.XPATH, "/html/body/div[5]/section[3]/div[2]/section/div[1]/div[3]/select")) ) line_count.click() select_count = WebDriverWait(driver, 20).until( EC.presence_of_element_located( (By.XPATH, "/html/body/div[5]/section[3]/div[2]/section/div[1]/div[3]/select/option[3]")) ) select_count.click() lines = driver.find_elements_by_class_name('product-listing') return lines
Then we will find the seller, card information and price. To do this, we will again use the class of elements by which they are located (in this way, Beautiful Soup and Selenium are very similar):
def get_prices(line): try: seller = line.find_element_by_class_name('seller__name').text.strip() except: seller = '' try: listing_condition = line.find_element_by_class_name( 'product-listing__condition').text.strip().lower() except: listing_condition = '' try: price = line.find_element_by_class_name('product-listing__price') except: price = '' price = price.text price = float(price.replace('$', '').replace(',', '')) data = {'seller': seller, 'listing_condition': listing_condition, 'price': price} write_csv(data)
Once we've found the data we are interested in, we can create a csv file from the data we received:
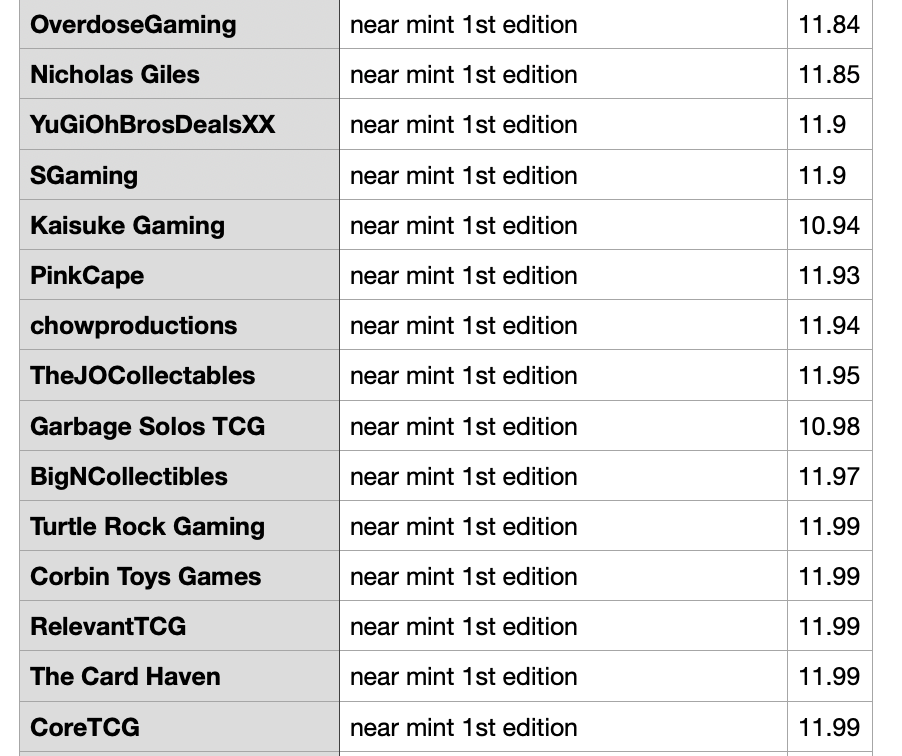
def write_csv(data): with open('selenium_ex.csv', 'a') as f: writer = csv.writer(f) writer.writerow((data['seller'], data['listing_condition'], data['price'])) def main(): url = 'https://shop.tcgplayer.com/yugioh/genesis-impact/meteonis-drytron?xid=pif9983579-a415-4d27-b667-77f6af8e74c0' driver = webdriver.Chrome(ChromeDriverManager().install()) lines = get_page_data(driver, url) for line in lines: get_prices(line) driver.quit() if __name__ == '__main__': main()
Here is the result we got:
Conclusion
Web scraping is a useful tool for retrieving information from web applications in the absence of an API. Using tools such as requests, BeautifulSoup, and Selenium it is possible to build tools for fetch significant amounts of data and convert it to a more convenient format for analysis.
Happy scraping!
Comments
Loading
No results found